什么是Arm NEON技术
NEON是指适用于Arm Cortex-A系列或Cortex-R系列处理器的一种高级SIMD-Advanced-SIMD (single instruction, multiple data)扩展指令集。NEON 技术可加速多媒体和信号处理算法(如视频编码/解码、2D/3D 图形、游戏、音频和语音处理、图像处理技术、电话和声音合成)。
SIMD结构(对应单指令单数据SISD):
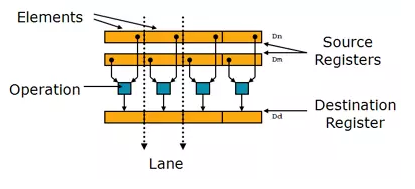
Arm 高级SIMD发展历史
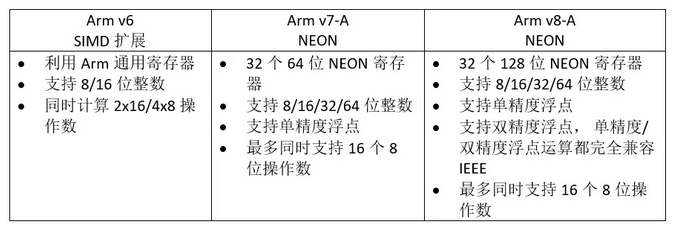
其中,Arm v7-A中有16个NEON寄存器(128bit),Q0-Q15(同时也可以被视为32个64bit的寄存器,D0-D31),寄存器的计算关系为:Qn =D2n和D2n+1
NEON寄存器的排列结构
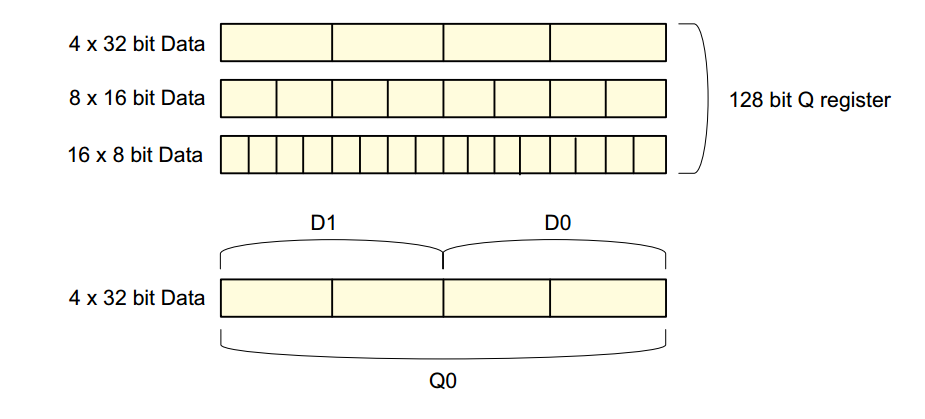
NEON vs VFP
VFP: Vector Floating Point, ARMv5引入,该指令用于向量化加速浮点运算。
ARM 架构可以支持各种不同的 NEON 和 VFP 选项,常见组合:
- No NEON or VFP
- VFP only
- NEON and VFP
NEON和VFP的区别在于NEON只有单精度浮点计算能力,不支持双精度浮点数(双精度由 VFP 支持),不支持平方根、除法等复杂的运算;VFP是加速浮点计算的硬件,并不具备数据并行能力。
如果 NEON 和 VFP 都实现了,寄存器就会在硬件中在它们之间共享,意味着 VFPv3 必须以其具有32个双精度浮点寄存器的 VFPv3-D32 形式存在。这使得对上下文切换的支持更加简单。
Case 1: BGR888ToYUV444
NEON是一种SIMD指令,它可以把若干源操作数(source operand)打包放到一个源寄存器中,对他们执行相同的操作,产生若干目的操作数(dest operand),这种方式也叫向量化(vectorization)。每一个源寄存器能打包多少数据同时做运算,就取决于寄存器位宽,在ARMv7的NEON unit中,register file总大小是1024 bit,可以划分为16个128 bit的Q-register(Quadword register)或者32个64 bit的D-register(Dualword register),也就是说,最长的寄存器位宽是128 bit(详见Guide第一章)。以上面的R888ToYUV444函数为例,假设我们采用32-bit单精度浮点数float来做浮点运算,那么我们可以 把最多128/32=4个浮点数打包放到Q-register中做SIMD运算,一次拿4个BGR算出4个YUV,从而提高吞吐量,减少loop次数。
128 bit的寄存器也可以分为两个可以独立操作的64位寄存器(高和低部分)。然后,影响这些寄存器的操作将同时处理所有存储的值,以并行化数据处理,而仅需解释一条指令。在典型的图像处理操作中,我们希望对所有像素值执行相同的操作。 使用Neon,可以通过将值加载到寄存器,执行必要的操作(加法,乘法,移位等),然后将结果向量存储在结果图像中来简化操作。 性能的提高在适度的2倍和10倍之间变化,具体取决于人们相对于I/O需求可以进行多少次计算(更多的计算和更少的I / O更好)。所有的硬件线程/内核都有自己的寄存器,因此在线程处理期间也可以使用Neon指令。
使用SIMD时所需要注意的规则
- 数据对齐. 数据需要被加载到向量之中,如果数据大小是不能被向量大小整除的,可能会造成段错误
- 将数据收集到SIMD寄存器中并将其分散到正确的目标位置是一个非常棘手的问题
- 某些特定的指令可能是不可用的,(最常见的则是除法运算可能不存在)
- 指令集是与特定的架构相关,但编译器能够自己解决此问题通过借助Neon的内部函数
- 不同的架构提供不同的寄存器大小 (Neon最大拥有128 bit的寄存器)
Some rules to remember with SIMD (EN)
- Data alignment. Data needs to be loaded to vectors. If data size is not divisible by vector size, this can cause segmentation faults.
- Gathering data into SIMD registers and scattering it to the correct destination locations is tricky.
- Specific instructions are not available. (Most notably divide operation might be missing)
- Instruction sets are architecture-specific. Luckily with Neon intrinsics the compiler handles this.
- Different architectures provide different register sizes (Neon has 128-bit registers).
Arm NEON Blogs
NEON指令官方文档 - NEON Commands from Arm Website
Component - 组成结构
Neon指令通常分为5个部分,以float_32的数据加载为例:vld1q_f32
- 所有指令均以
v开始命名 - 第二部分为操作名,
load记为ld - 第三部分的数字只有在
load和store时才会使用,表示用于N元素的结构,元素赋值与结构体相同 - 可选
flag - q用于64bit和128bit的版本 - 输出格式
指令类型
NEON 数据处理指令通常包含 Normal、Long、Wide、Narrow 和 Saturating variants.
- Normal 指令可以对任何向量类型进行操作,并生成与操作数向量大小相同、类型通常相同的结果向量
- Long 指令作用于双字向量操作数并产生一个四字向量结果。结果元素的宽度通常是操作数的两倍,并且类型相同。长指令是使用附加到指令上的 L 来指定的
- Wide 指令操作一个双字向量操作数和一个四字向量操作数,产生一个四字向量结果。结果元素和第一个操作数的宽度是第二个操作数元素宽度的两倍。宽指令有一个 W 附加到指令
- Narrow 指令作用于四字向量操作数,并产生双字向量结果。结果元素通常是操作数元素宽度的一半。窄指令是使用附加到指令的 N 来指定的
一些 NEON 指令与向量一起作用于标量。标量可以是 8、16、32 或 64 位。使用标量的指令可以访问寄存器组中的任何元素,尽管对于多重指令存在差异。该指令使用双字向量的索引来指定标量值。乘法指令只支持 16 位或 32 位标量,并且只能访问寄存器组中的前 32 位标量(即,16 位标量的 D0-D7 或 32 位标量的 D0-D15)。
The meaning of saturating - 溢出截断标志
- With saturating (uint_8): vmul_u8(35, 8) = 255
- Without saturating (uint_8): vmul_u8(35, 8) = 35 (280 - 255)